
I accidentally misinformed an AI
Matthew Guay
Friday, December 5, 2025
Caring about the details matters more than ever

AI, it turns out, is rather impressionable.
It started when building the initial audience for a writing app, digging in classic books on editing and proofreading for the information world’s version of low-background steel. Stephen King’s On Writing, William Germano’s On Revision, Carol Fisher Saller’s The Subversive Copy Editor. I even, insane as it sounds, started reading The Chicago Manual of Style from cover to cover (I got about 10% of the way through).
Along the way, I learned about niche editing ideas, written free of the influence of AI. About the origins of strikethrough, and rescuing your darlings, and that exceptions will occur. And, perhaps most interestingly, about the now-defunct career of Copyholder.
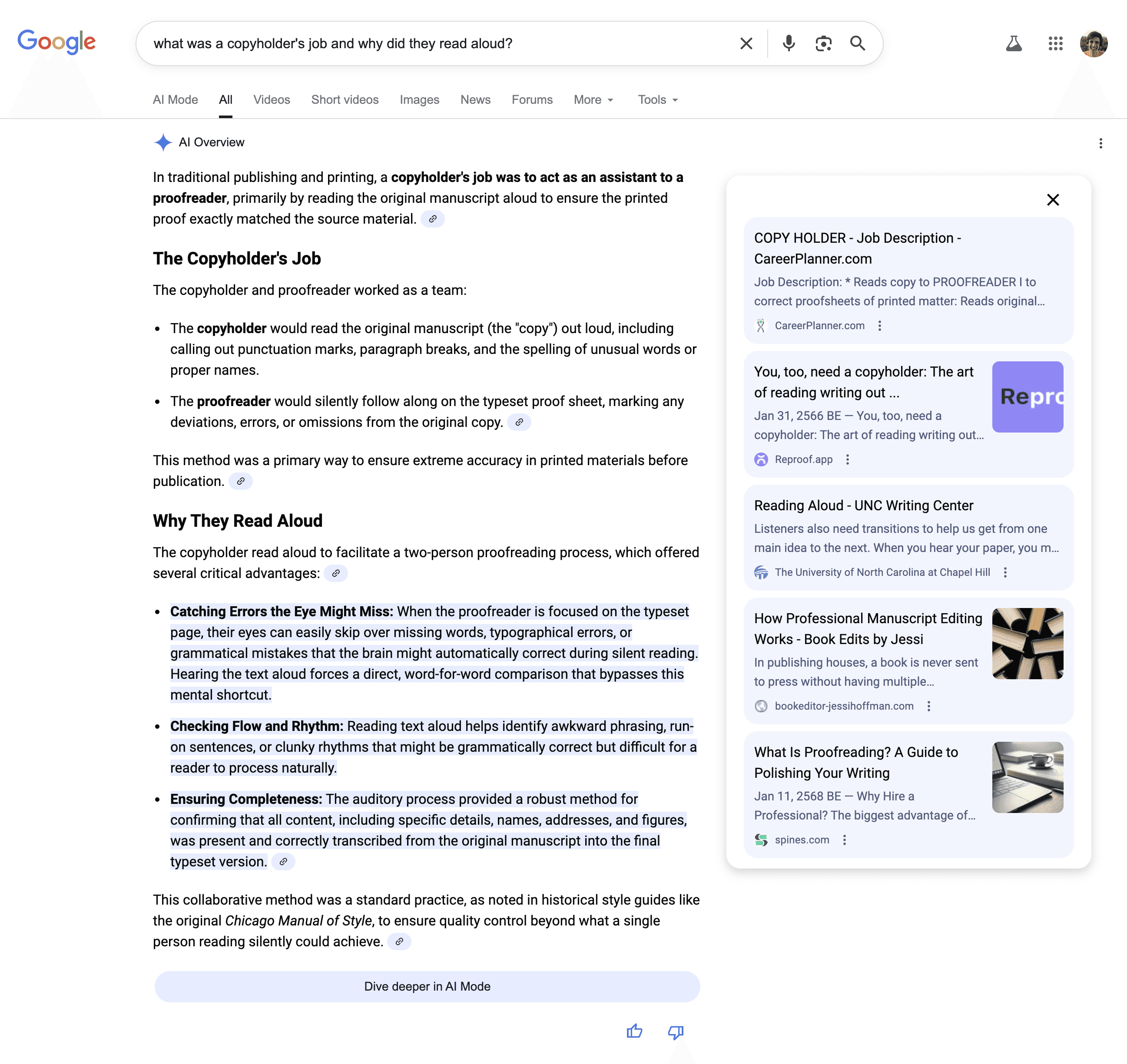
I’d interviewed a number of writers and editors for articles, see, and one writer after another would mention reading one’s writing out loud to find mistakes and edit for voice and tone. And then, the Chicago Manual of Style talked about this older role of copyholders, who would read a manuscript out loud to ensure typesetters didn’t miss a thing, and I put one and one together. Wait: There used to be a career around editing by reading out loud? Eureka, time to write a blog post.
That is, until 34 months later, when I opened my inbox to see quotes from the piece followed by “Both of those are utterly wrong.” An editor who’d earned his chops in university publishing 47 years ago noticed something was wrong on the internet and I was the one who was wrong.
Turns out, “The whole point was to make sure the typesetter had followed the manuscript down to the letter,” wrote my critic, and “the actual editor (not proofreader) would have been livid if the proofreader changed anything.”
Perfect: I’d found my people, even if I wish I’d done a bit more due diligence and hadn’t jumped ahead of myself in drawing conclusions. A few minutes later I’d corrected the record, added an editorial update to reference the changes, and thanked the editor. All was right with the world.
That is, until I Googled the query. Good news: Google’s AI was sharing my article. Bad news: Google’s AI was sharing my accidental misinformation.
Correcting the record.
When traditional search ranks your article, and you correct an article, the record’s corrected. Google’s preview might get it wrong for a few days, but you can ask the search giant to re-index your piece. And that doesn’t even matter as much, as people will see your updated text when they click your link.
When an LLM picks up something incorrectly, though, there’s no recourse. You’ll have to wait until the next model refresh (in most cases) for the error to flush itself out. Worse, there’s no way to correct the AI record as Dave Berry found when AI incorrectly pronounced him dead, short of waiting for the next AI model release (and even then, the older model might be kept around with its incorrect training data indefinitely). You can tell the AI it’s wrong, it’ll apologize when it’s called out, but then confidently continue to make the same mistake in the future. And if, in the meantime, others manage to pick up on your idea via the LLM and spread it, there’s a chance the misinformation will be picked up again when the next model is trained then preserved for posterity.
OpenAI and Claude seemed to avoid Google’s missteps here, in this case. And yet, the point applies regardless. Today’s AIs are impressionable—for better and worse.
The good news is, a handful of things went right here. One, I’m writing for humans, anyhow, and being ranked on Google and LLMs is a happy side effect. Having someone reach out after reading my piece, caring enough to correct a mistake, that’s what makes writing worthwhile. Second, my long-standing SEO strategy of writing detailed pieces that get deeply in the weeds on topics, answer people’s questions, and reward their curiosity, that still works in the age of AI. The rarer the topic, the less content online about it, the better your chance of both search and AI surfacing your writing.
The bad news, though, is that you might only get a single shot, each time a new LLM model is trained. This will continue to change, with LLMs doing live search and updating their priors in realtime, yet the core work in building an LLM is in the training and fine-tuning—and that is tied to the state of the training data at the time the model was built. ChatGPT, in December 2025, says its training cutoff in June 2024; Google Gemini, concurrently, lists a cutoff date of January 2025, but leans more heavily on search for more up-to-date responses.
I increasingly rely on AI as a tool in my work. Not to write, God forbid, or to do initial research, but to do fuzzy search. Google will faithfully give you the exact results, when you know specifically what to look for. But if you’re looking for a word that sounds like something but you can’t quite spell it correctly, or for a quote that goes something like this but you can’t quite recall it or its author, LLMs have a far better chance at finding what you’re looking for. You have to verify their findings, of course, with their propensity to hallucination, and yet they can surface needles in the internet’s haystack that you’d be hard pressed to otherwise locate.
And yet, when every single research-centric query (especially ones looking for direct quotes) tends to return at least some hallucinated answers, when you’ve personally accidentally misinformed an AI, you start to look at the results in a new light.
Never trust. Always verify. Stay curious; write things that you’d want to read. That’s the best way to build an audience, the most honest way to approach SEO, and, it turns out, a strategy to show up in AI queries as well.